数据结构与算法
❤️ 算法解题模板
- 数据结构
- 二叉树
- 二叉树遍历
- 非递归遍历
- 利用栈来保存已经返回的元素,用于原路返回
- 递归遍历
- DFS 深度搜索
- DFS 从上到下 (递归)
- 最终结果通过指针参数传入
- DFS 从下到下(分治法)
- 递归返回结果最后合并
- DFS 从上到下 (递归)
- BFS 层次遍历
- DFS 深度搜索
- 非递归遍历
- 分治法应用
- 快排
- 归并
- 遍历二叉树
- 二叉搜索树应用
- 给定一个二叉树,判断其是否是一个有效的二叉搜索树。
- 思路1:中序遍历是否有序
- 思路2:分治法,判断 左 MAX < 根 < 右 Min
- 给定一个二叉树,判断其是否是一个有效的二叉搜索树。
- 二叉树遍历
- 链表
- null 异常处理
- dummy node 哨兵节点
- 快慢指针
- 插入一个节点到排序链表
- 从一个链表中移除一个节点
- 翻转链表
- 合并两个链表
- 找到链表的中间节点
- 栈和队列
- 二进制
- 二叉树
- 基础算法
- 二分查找
- 使用场景一般是有序数组的查找
- 排序算法
- 动态规划
- 场景
- 求最大/最小值
- 求是否可行
- 求可行个数
- 不能排序或者交换
- 和递归关系
- 递归是一种程序的实现方式:函数的自我调用
- 动态规划是一种解决问题的思想,大规模问题的结果,是由小规模问题的结果运算得来的。动规可用递归来实现
动态规划就是把大问题变成小问题,并解决了小问题重复计算的方法称为动态规划
- 场景
- 二分查找
- 算法思维
- 递归思维
- 斐波那契数列
- 改进版本 动态规划版本
- 斐波那契数列
- 滑动窗口
- 和双指针题目类似,更像双指针的升级版
- 核心是维护一个窗口集,根据窗口集来进行处理
- 给定一个字符串,请你找出其中不含有重复字符的 最长子串 的长度
- 给你一个字符串 S、一个字符串 T,请在字符串 S 里面找出:包含 T 所有字母的最小子串
- 二叉搜索树
- 回溯法
- 是 DFS 深度搜索的一种
- 回溯算法就是纯暴力穷举,复杂度一般都很高
- 常用语遍历列表所有子集
- 穷尽所有可能
- 核心就是从选择列表做一个选择,然后一直递归往下搜索答案,如果遇到路径不通,就返回来插销这次选择
- 题目
- 括号生成
- 给定一组不含重复元素的整数数组 nums,返回该数组所有可能的子集
- 递归思维
// 分治法模板
// 递归返回条件
// 分段处理
// 合并结果
func traversal(root *TreeNode) ResultType {
// nil or leaf
if root == nil {
// do something and return
}
// Divide
ResultType left = traversal(root.Left)
ResultType right = traversal(root.Right)
// Conquer
ResultType result = Merge from left and right
return result
}
// 回溯法模板
result = []
func backtrack(选择列表,路径):
if 满足结束条件:
result.add(路径)
return
for 选择 in 选择列表:
做选择
backtrack(选择列表,路径)
撤销选择
入门
- 数据结构是一种数据的表现形式,如链表、二叉树、栈、队列等都是内存中一段数据表现的形式。
- 算法是一种通用的解决问题的模板或者思路,大部分数据结构都有一套通用的算法模板。
算法可视化
https://algorithm-visualizer.org/
考察维度
- 思维能力
- 代码实现能力
- 复杂度计算
- O(logn) 优于 O(n)
伪代码
- 是一种用来思考程序问题的工
- 缩进表示块结构
- 变量直接使用无需声明。一般变量默认为局部变量
- 数据访问通过数组名和下标的方式访问。
- 赋值语句用符号←表示
基本概念
- 数组和列表:最常用的数据结构。
- 栈和队列:与列表类似但更复杂的数据结构。
- 链表:如何通过它们克服数组的不足。
- 字典:将数据以键-值对的形式存储。
- 散列:适用于快速查找和检索。
- 集合:适用于存储只出现一次的元素。
- 二叉树:以层级的形式存储数据。
- 图和图算法:网络建模的理想选择。
- 算法:包括排序或搜索数据的算法。
- 高级算法:动态规划和贪心算法。
理解数据结构,可以为问题选择最优的数据结构,在某些操作上非常高效
如何应对算法题
没有所谓的高频题,只有高频知识点
- 比如两数之和考察的就是哈希表
- 如果暴力两重循环必挂
- 不会是原题
- 两数之和可以改为两树之乘积等等
- 背后考察的还是哈希表
- 两数之和还可以改为多数之和
- 要查两次表
- 两数之和可以改为两树之乘积等等
- 二分查找优于哈希表
- 哈希表的构建时间复杂度是O(n)
- 二分查找可以把时间复杂度降到 O(logn)
到低准备多少道题?
- 我觉得先刷够
100道题就可以了 - 按照分类刷题(相似的题目一起刷)
- 字符串
- 链表
- 数学题
- 排序
- 查找
- 二叉树
- 可能性问题
- 回文
- 路径题
- 按照解法刷题
- 双指针
- 递归
- 一题多解
极客时间-算法面试通关40讲 课程大纲
前端瓶子君 - 脑图
数组篇
- 图解leetcode88:合并两个有序数组
- 字节&leetcode1:两数之和
- 腾讯&leetcode15:三数之和
- 腾讯:数组扁平化、去重、排序
- leetcode349:给定两个数组,编写一个函数来计算它们的交集
- 华为&leetcode146:设计和实现一个LRU(最近最少使用)缓存机制
- 阿里算法题:编写一个函数计算多个数组的交集
链表
- leetcode21:合并两个有序链表
- 有赞&leetcode141:判断一个单链表是否有环
- 图解leetcode206:反转链表
- leetcode876:求链表的中间结点
- leetcode19:删除链表倒数第 n 个结点
- 图解字节&leetcode160:编写一个程序,找到两个单链表相交的起始节点
字符串
- 字节&leetcode151:翻转字符串里的单词
- 图解拼多多&leetcode14:最长公共前缀(LCP)
- 百度:实现一个函数,判断输入是不是回文字符串
- 字节&Leetcode3:无重复字符的最长子串
- Facebook&字节&leetcode415: 字符串相加
栈
- 字节&leetcode155:最小栈(包含getMin函数的栈)
- 图解腾讯&哔哩哔哩&leetcode20:有效的括号
- leetcode1047:删除字符串中的所有相邻重复项
- leetcode1209:删除字符串中的所有相邻重复项 II
- 面试真题:删除字符串中出现次数 >= 2 次的相邻字符
队列
哈希表
- 腾讯&leetcode349:给定两个数组,编写一个函数来计算它们的交集
- 字节&leetcode1:两数之和
- 腾讯&leetcode15:三数之和
- leetcode380:常数时间插入、删除和获取随机元素
- 剑指Offer:第一个只出现一次的字符
二叉树
二叉树的遍历
- 字节&leetcode144:二叉树的前序遍历
- 字节&leetcode94:二叉树的中序遍历
- 字节&leetcode145:二叉树的后序遍历
- leetcode102:二叉树的层序遍历
- 字节&leetcode107:二叉树的层次遍历
重构二叉树
二叉树进阶
- leetcode105:从前序与中序遍历序列构造二叉树
- leetcode105:从前序与中序遍历序列构造二叉树
- 腾讯&leetcode104:二叉树的最大深度
- 字节&腾讯leetcode236:二叉树的最近公共祖先
- 剑指Offer&leetcode110:平衡二叉树
- 字节&leetcode112:路径总和
- 剑指Offer&leetcode101:对称二叉树
堆
图
编程题
- 携程&蘑菇街&bilibili:手写数组去重、扁平化函数
- 百度:模版渲染
- 百度:什么是浅拷贝和深拷贝?有什么区别?如何实现 Object 的深拷贝
- 阿里&字节:手写 async/await 的实现
- 编程题:用最简洁代码实现 indexOf 方法
- 阿里编程题:实现一个方法,拆解URL参数中queryString
- 字节:输出以下代码运行结果,为什么?如果希望每隔 1s 输出一个结果,应该如何改造?注意不可改动 square 方法
王争 - 数据结构和算法必知必会的50个代码实现
数组
- 实现一个支持动态扩容的数组
- 实现一个大小固定的有序数组,支持动态增删改操作
- 实现两个有序数组合并为一个有序数组 链表
- 实现单链表、循环链表、双向链表,支持增删操作
- 实现单链表反转
- 两个有序的链表合并
- 删除链表倒数第 n 个结点
- 实现求链表的中间结点
- 链表中环的检测 栈
- 用数组实现一个顺序栈
- 用链表实现一个链式栈
- 编程模拟实现一个浏览器的前进、后退功能 队列
- 用数组实现一个顺序队列
- 用链表实现一个链式队列
- 实现一个循环队列 递归
- 编程实现斐波那契数列求值f(n)=f(n-1)+f(n-2)
- 编程实现求阶乘n!
- 编程实现一组数据集合的全排列 排序
- 实现归并排序、快速排序、插入排序、冒泡排序、选择排序
- 编程实现O(n)时间复杂度内找到一组数据的第K大元素 二分查找
- 实现一个有序数组的二分查找算法
- 实现模糊二分查找算法(比如大于等于给定值的第一个元素) 散列表
- 实现一个基于链表法解决冲突问题的散列表
- 实现一个LRU缓存淘汰算法 字符串
- 实现一个字符集,只包含a~z这26个英文字母的Trie树
- 实现朴素的字符串匹配算法 二叉树
- 实现一个二叉查找树,并且支持插入、删除、查找操作
- 实现查找二叉查找树中某个节点的后继、前驱节点
- 实现二叉树前、中、后序以及按层遍历 堆
- 实现一个小顶堆、大顶堆、优先级队列
- 实现堆排序
- 利用优先级队列合并K个有序数组
- 求一组动态数据集合的最大Top K 图
- 实现有向图、无向图、有权图、无权图的邻接矩阵和邻接表表示方法
- 实现图的深度优先搜索、广度优先搜索
- 实现Dijkstra算法、A*算法
- 实现拓扑排序的Kahn算法、DFS算法 回溯
- 利用回溯算法求解八皇后问题
- 利用回溯算法求解0-1背包问题 分治
- 利用分治算法求一组数据的逆序对个数 动态规划
- 0-1背包问题
- 最小路径和
- 编程实现莱文斯坦最短编辑距离
- 编程实现查找两个字符串的最长公共子序列
- 编程实现一个数据序列的最长递增子序列
算法复杂度
- 对于一个算法、它的时间复杂度和空间复杂度往往是相互影响的
常见复杂度

时间复杂度
- 描述算法运行的时间
- O(1)
- O(n)
- 一个 for 循环
- O(n ^ 2)
- 嵌套 2 个 for 循环
- O(log n) 对数复杂度
- O(2 ^ n) 指数复杂度
空间复杂度
- 算法运行过程中临时占用空间大小的考量
- 数据结构可以优化空间复杂度
数据结构***
数据结构的存储结构
- 顺序存储
- 连续的存储单元
- 数组
- 优势
- 按照下标查询 O(1)
- 劣势
- 插入和删除
- 最差情况下,挪动所有元素,平均O(n)
- 插入和删除
- 连续的存储单元
- 链式存储
- 指针存放地址
- 存储单元可以不连续
- 频繁变化的数据,顺序存储不合适,操作复杂度高
- 线性数据结构
- 数组
- 链表
没有完美的数据结构
- 没有完美的数据结构,如果有,别的数据结构就没必要存在了
- 如何寻找匹配的数据结构?
- 一个动态平衡的过程
字符串
- 应用
- 翻转字符串里的单词
- 最长公共前缀 (LCP)
- 判断回文字符串
- 无重复字符的最长子串
- 字符串相加
1-1 👌 整数翻转
https://leetcode-cn.com/problems/reverse-integer/
- 通过数组的 reverse 方法
- 把整数看做字符串
- 不管有没有符号
- 先反转字符串
- 利用数组的 reverse 方法
- 最后处理符号
- 先反转字符串
- 注意处理字符范围
var reverse = function(x) {
if(typeof x !== 'number') return
var MAX = Math.pow(2, 31) - 1,
MIN = -Math.pow(2, 31)
var reverseNum = Number(`${Math.abs(x)}`.split('').reverse().join(''))
reverseNum = x > 0 ? reverseNum : (0 - reverseNum)
if(MIN > reverseNum || reverseNum > MAX ) {
return 0
}
return reverseNum
};
- 弹出和推入数字 & 溢出前进行检查
- 当 temp = rev * 10 + pop 会导致栈溢出
var reverse = function(x) {
let rev = 0
const MAX_VALUE = Math.pow(2, 31) - 1,
MIN_VALUE = -Math.pow(2, 31)
while(x != 0 ) {
const pop = x % 10
x = parseInt(x / 10)
if(rev > MAX_VALUE / 10 || (rev === MAX_VALUE / 10) && pop > (MAX_VALUE % 10)) { return 0}
if(rev < MIN_VALUE / 10 || (rev === MIN_VALUE / 10) && pop < (MIN_VALUE % 10)) { return 0}
rev = rev * 10 + pop
}
return rev
};
1-2 有效的字母异位词
1-3 字符串转换整数
2-1 报数
2-2 👌反转字符串
- 题目
- 输入字符串以字符数组 char[] 的形式给出
- 不要给另外的数组分配额外的空间,你必须原地修改输入数组、使用 的额外空间解决这一问题。
- 递归
- 空间复杂度不满足题目条件
- 双指针
- 时间复杂度:O(n)。执行了 N/2 次的交换。
- 空间复杂度 O(1)
2-3 👌字符串中的第一个唯一字符
https://leetcode-cn.com/problems/first-unique-character-in-a-string/
- 哈希表
- 时间复杂度 O(n)
- 因为有两次遍历,且每次遍历都只有一层没有嵌套
- 空间复杂度 O(1)
- 时间复杂度 O(n)
var firstUniqChar = function(s) {
var map = new Map()
for(var i = 0; i < s.length; i++) {
map.has(s[i]) ? map.set(s[i], map.get(s[i]) + 1) : map.set(s[i],1)
}
for(var i = 0; i < s.length; i++) {
if(map.get(s[i]) === 1) return i
}
return -1
};
3-1 👌验证回文字符串
https://leetcode-cn.com/problems/valid-palindrome/
- 双指针 - 在原字符串上进行比较
- 去除非字母和数字
- 然后依次比较首尾字符
- 如有一个不同,return false
- 时间复杂度 O(n)
- 循环 n / 2
- 空间复杂度
- O(1)
- 申请了2个变量
- O(1)
- 用栈来实现字符串的反转
- 出栈的顺序是反转的
- 比对反转的字符串和原始字符串
var isPalindrome = function(s) {
s = s.replace(/[^A-Za-z0-9]/g,'').toLowerCase()
var i = 0,
j = s.length - 1
while(i < j) {
if(s[i] !== s[j]) return false
i++
j--
}
return true
};
3-2 实现 strStr()
3-3 最长公共前缀
3-4 最长回文子串
数学
- 在实际的面试中,用到的数学知识大纲为初中,极少可能超纲到高中
1-1 👌罗马数字转整数
- 通常情况下,罗马数字中小的数字在大的数字的右边
- 有六种情况,小数在前
- IV IX
- XL XC
- CD CM
- 方法1 不罗列特殊情况,往后看多一位
- 1 不需要罗列6种情况
- 2 比较后者和前者的大小
- 如果后者大于前者,
- 差值 = 后者
map[s[i + 1]]- 前者的值map[s[i]] - i + 2
- 差值 = 后者
- 如果不大于
- i + 1
- 如果后者大于前者,
- 方法2 罗列特殊情况
- 往后多看一位
- 匹配特殊情况
- i += 2
- 往后多看一位
- 方法3,最后判断字符串是否包含特殊子串
- 单个字符都加起来
- 最后判断字符串是否包含特殊子串
- 枚举特殊子串的差值
- 2
- IV 和 VI 的区别 6 - 4 = 2
- IX 和 XI 的区别 11 - 9 = 2
- 20
- 200
- 2
// 时间复杂度 O(n)
// 空间复杂度 O(1) 一个变量,一个 hashMap
var romanToInt = function(s) {
var map = {
I: 1,
V: 5,
X: 10,
L: 50,
C: 100,
D: 500,
M: 1000
}
var num = 0
for (var i = 0; i < s.length; ) {
if (map[s[i + 1]] && map[s[i + 1]] > map[s[i]]) {
num += map[s[i + 1]] - map[s[i]]
i += 2
} else {
num += map[s[i]]
i += 1
}
}
return num
};
步进值为1
var romanToInt = function(s) {
var hashNum = {
"I":1,
"V":5,
"X":10,
"L":50,
"C":100,
"D":500,
"M":1000
}
var result = 0;
for(let i = 0;i<s.length;i++){
hashNum[s[i]] < hashNum[s[i+1]] ? result -= hashNum[s[i]] : result += hashNum[s[i]]
}
return result;
};
Fizz Buzz 和 计数质数
2-1 3 的幂
Execel 表格序号、快乐数和阶乘后的零
3-1 👌Pow(x, n)
- 暴力
- 最垃圾的解法
- 分治 + 递归
var myPow = function(x, n) {
if(n === 0) return 1
var base = n > 0 ? x : 1 / x
var result = 1
for(var i = 0; i < Math.abs(n); i++) {
result *= base
}
return result
};
var myPow = function(x, n) {
if(n === 0) return 1
else if (n === 1) return x
else if (n === -1) return 1 / x
var base = n > 0 ? x : 1 / x
var half = parseInt(n / 2)
var result = myPow(x, half)
if(n % 2 === 0) {
result *= result
} else {
result = result * result * base
}
return result
};
最终版本,降低 n 的幂次,防止栈溢出
var myPow = function(x, n) {
if (n === 0) return 1
if (n === 1) return x;
if (n < 0) return 1 / myPow(x, -n)
if (n % 2 === 1) return x * myPow(x, n - 1)
return myPow(x * x, n / 2)
};
- 折半计算
两数相除、分数到小数和 x 的平方根
数组
- 对于非科班的同学,可能对数据结构的认识就到数组为止了。
- JS 的数组是一种特殊的对象
- 其索引值是字符串
- 可以给该对象添加属性
- 但是 JS 引擎会发现,我们在像使用常规对象一样使用数组,那么针对数组的优化就不在试用了,可能会带来性能问题。
- 关于长度
- 与其他编程语言不通,JS 中数组的长度可以随时改变,并且其数据在内存中也可以不连续。
- JS 中的数组也是一个比较特殊的对象
- 索引是该对象的属性
- 可以给数组对象加属性
- 题目
- 合并两个有序数组
- 两数之和
- 三数之和
- 数组扁平化、去重、排序
- 两个数组的交集
- 设计和实现一个 LRU 缓存机制
- 计算多个数组的交集
基本操作
- 插入,在给定索引位置插入一个元素
- 删除,删除指定位置的元素
- 获取任一位置的元素
- 获取数组的长度
优势
- 数组适合查找操作
- 根据下标随机访问的时间复杂度为 O(1)
- 劣势
- 插入、删除复杂度都是 O(n)
V8 中关于数组的两种存储模式
// The JSArray describes JavaScript Arrays
// Such an array can be in one of two modes:
// - fast, backing storage is a FixedArray and length <= elements.length();
// Please note: push and pop can be used to grow and shrink the array.
// - slow, backing storage is a HashTable with numbers as keys.
class JSArray: public JSObject {
public:
// [length]: The length property.
DECL_ACCESSORS(length, Object)
// Number of element slots to pre-allocate for an empty array.
static const int kPreallocatedArrayElements = 4;
};
- Fast 快数组
- 线性的存储方式
- push 和 pop 操作会对数组进行动态的扩容和缩容
- 创建的新空数组,默认的存储方式是快数组
- 快数组以空间换时间,申请了连续内存,提高效率,但是比较占内存。
- 根据索引来定位
- Slow 慢数组
- 基于 Hash 表来实现
- 根据 k-v 来定位
- 不用开辟大块连续的存储空间,节省内存,效率比快数组低
- 以时间换空间,不需要申请连续的空间,节省了内存,但是效率较低。
- 快慢的转变
1-1 👌翻转数组
https://leetcode-cn.com/problems/rotate-array/
- 至少有三种不同的方法可以解决这个问题
- unshift + pop
- 时间 O(n) 空间 O(1)
- unshift + splice 方法
- unshift + pop
- 要求使用空间复杂度为 O(1) 的 原地 算法。
- 时间 O(1) 空间 O(1)
var rotate = function(nums, k) {
// 如果 k === nums.length,就不用循环了
k = k % nums.length
for(var i = 0; i < k; i++) {
nums.unshift(nums.pop())
}
return nums
};
var rotate = function(nums, k) {
var l = nums.length
k = k % l
nums.unshift(...nums.splice(l - k, k))
return nums
};
1-2 只出现一次的数字
1-3 👌两数之和
给定一个整数数组nums和一个目标值target,请你在该数组中找出和为目标值的那两个整数,并返回他们的数组下标。
- 暴力法 算了
- 哈希表法
- 时间 O(n)
- 空间 O(n) 申请了大小为 n 的空间
1-4 旋转图像
2-1 从排序树组中删除重复项
加一、买股票的最佳时机和移动零
3-1 两个数组的交集
一周中的第几天、有效的数独、除自身以外数组的乘积和存在重复元素
4-1 字谜分组
4-2 三数之和
4-3 无重复字符的最长子串
4-4 矩阵置零
4-5 递增的三元子序列
链表 Link-List
- 是一种线性数据结构
- 分类
- 单链表
- 变体 - 有头尾指针的链表
- 双链表
- 查询链表元素方便
- 有 prev 和 next 指针
- 单链表
- 优势
- 插入和删除快 O(1)
- 劣势
- 查询慢 O(n)
- 你讲学到
- 了解单链表和双链表的技巧
- 实现遍历、插入和删除操作
- 双指针技巧
Add(value)
n <- node(value)
if head = ø
head <- n
tail <- n
else
tail.next <- n
tail <- n
end if
end Add
复杂度
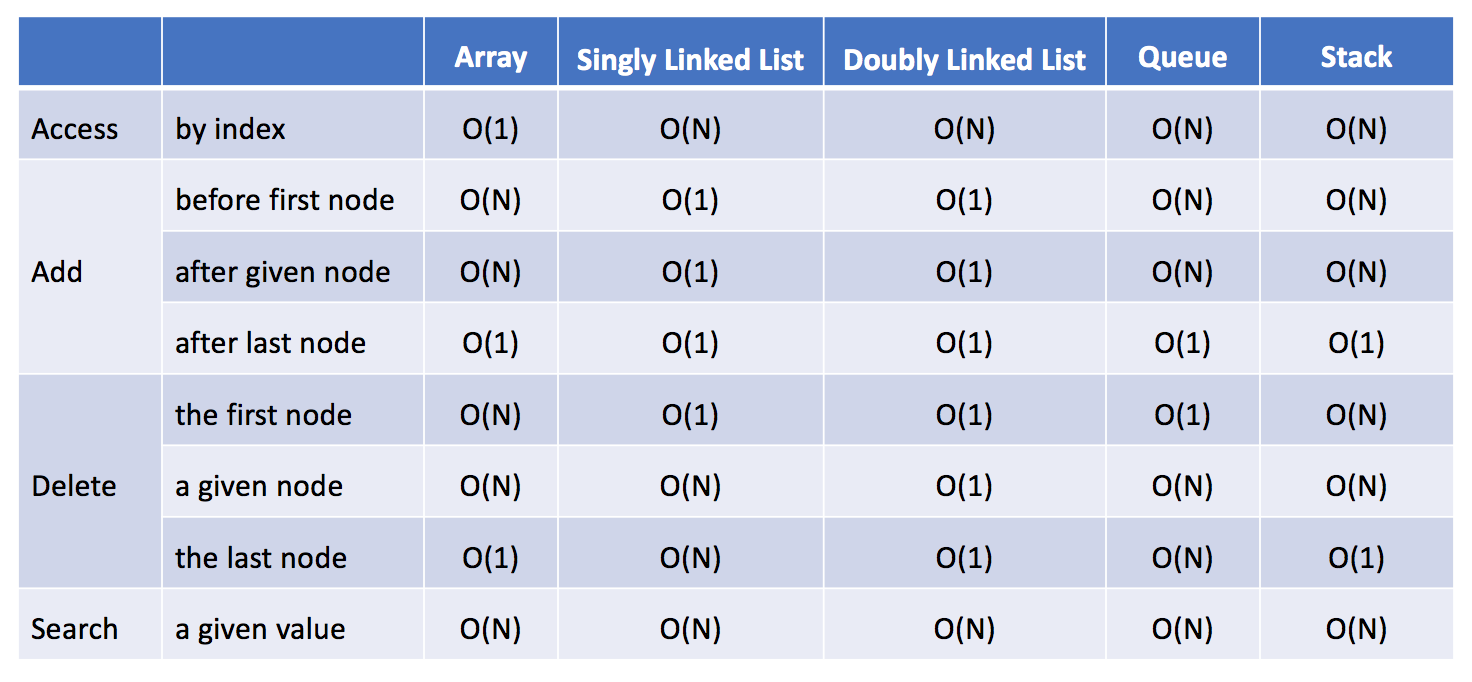
- access
- by index
- add
- before first node
- after given node
- after last node
- delete
- the first node
- a given node
- the last node
- search
- a given node
边界
- 如果链表为空,代码会不会报错
- 如果链表只有一个元素
- 两个元素呢?
- 在头部和尾部插入或删除?
题目
- 基本应用
- 从尾到头打印链表
- 删除链表中的节点
- 反转链表
- 复杂链表的复制
- 求链表中的中间节点
- 删除链表倒数第 n 个节点
- 合并两个有序链表
- 环类题目
- 判断一个单链表是否有环
- 链表环的入口节点
- 约瑟夫环
- 双指针
- 两个链表的公共节点
- 链表倒数第k个节点
- 相交链表
数组和链表比较
- 数组
- 随机访问 O(1)
- 查找、删除 O(n)
- 链表
- 随机访问 O(n)
- 查找、删除 O(1)
设计一个单链表
class Node{
constructro(val) {
this.next = null
this.val = val;
}
}
class LinkedList {
constructor() {
this.head = new Node('head')
}
// 用于查找
find(val) {
let currentNode = this.head;
while(currentNode && currentNode.val !== item) {
currentNode = currentNode.next
}
return currentNode === null ? -1 : currentNode
}
// 指定元素向后插入节点
// val: 新节点的 value
// node: 插入位置
insert(val, node) {
const currtNode = this.find(node)
if (currtNode === -1) {
console.log('未找到插入位置')
return
}
const newNode = new Node(val)
newNode.next = currtNode.next
currtNode.next = newNode
}
// 删除节点
// 要删除的节点
remove(node) {
Object.assign(node, node.next)
}
}
解题技巧 - 快慢双指针
- 引入
- 判断链表中是否有环
- 快慢指针能解决大部分的链表问题,还是挺好用的
- 两个指针从不同位置出发:一个从始端开始,另一个从末端开始;
- 两个指针以不同速度移动:一个指针快一些,另一个指针慢一些。
- 每次移动慢指针一步,而移动快指针两步
- 应用
- 判断链表中是否有环
- 相交链表
- 删除链表的倒数第 N 个节点
- 回文链表
// 给定一个链表: 1->2->3->4->5, 和 n = 2.
// 当删除了倒数第二个节点后,链表变为 1->2->3->5.
var removeNthFromEnd = function(head, n) {
let first = head; // 慢指针
for (let i = 0; i < n; i++) {
first = first.next;
}
if (!first) return head.next; // 当链表长度为n时,删除第一个节点
let second = head; // 快指针
while (first.next) {
first = first.next;
second = second.next;
}
second.next = second.next.next;
return head;
};
移除链表元素
- 难点:当要删除的一个或多个节点位于链表的头部时,事情会变得复杂。
- 可以通过哨兵节点去解决它,哨兵节点广泛应用于树和链表中,如伪头、伪尾、标记等,它们是纯功能的,通常不保存任何数据,其主要目的是使链表标准化,如使链表永不为空、永不无头、简化插入和删除
- 要在头部添加一个假的头节点
- 防止要删头部
- 复杂度
- 时间复杂度:O(N),只遍历了一次。
- 空间复杂度:O(1)。
var removeElements = function(head, val) {
const newHead = new ListNode(-1)
newHead.next = head
let cur = newHead
while (cur.next !== null) {
if (cur.next.val === val) {
cur.next = cur.next.next
} else {
cur = cur.next
}
}
return newHead.next
};
1-1 👌回文链表 isPalindrome
有3个办法
字符串拼接
递归
双指针
字符串拼接
- 定义两个变量存储每个节点的 val
- 反向遍历的字符串 每次都是
${node.val} + ${reverseStr}
- 反向遍历的字符串 每次都是
- head = head.next
- 终止条件
- 一直遍历到 Null 为止
- while(head)
- 复杂度
- 遍历1次,时间复杂度 O(n)
- 空间复杂度 O(1)
- 定义了2个变量
- 定义两个变量存储每个节点的 val
/**
* Definition for singly-linked list.
* function ListNode(val) {
* this.val = val;
* this.next = null;
* }
*/
/**
* @param {ListNode} head
* @return {boolean}
*/
var isPalindrome = function(head) {
// 字符串拼接,比对结果
let forwardStr = '',
reverseStr = '';
while(head) {
const nodeVal = head.val;
forwardStr = forwardStr + nodeVal
reverseStr = nodeVal + reverseStr
head = head.next;
}
return forwardStr === reverseStr
};
递归
- 执行用时:84 ms 战胜 42%
- 复杂度
- 时间 O(n) 只对链表进行了一次遍历
- 空间 O(1) 只申请了一个全局变量 Pointer
- 关键要定义一个递归函数外的变量 pointer
- 看这个递归退出条件 !head
- 此时执行到这里
- const res = reverseLinkList(head.next) && (pointer.val === head.val);
- head 此时是最后一个节点
- reverseLinkList(head.next) 返回 true
- 短路语法
- 执行后面的判断
- 判断第一个节点和最后一个节点的值一样不
- 一样 返回 true
- 不一样 返回 false
- point 递增
- 返回 判断的结果
- 然后返回上一次栈
- 此时 head 是倒数第二个节点
- 上一层返回的结果如果是 true
- 判断倒数第二个和第二个节点的值
- 如果是 false
- pointer 递增
- 返回 false
- 因为是返回false
- 后面的判断都不会执行
- pointer 还好递增
- 直到第一次递归
- 此时 pointer 也到了链表的结尾 null
- 还是返回 false
- 此时执行到这里
class ListNode {
constructor (val) {
this.val = val
this.next = null
}
}
var isPalindrome = function(head) {
let pointer = head;;
function reverseLinkList (head) {
if (!head) return true;
// 递归逆序遍历
const res = reverseLinkList(head.next) && (pointer.val === head.val);
// pointer 指针不断向后指,进行正序遍历
pointer = pointer.next;
console.log(pointer)
return res;
}
return reverseLinkList(head);
};
// 测试用例
var nodeA = new ListNode(1);
var nodeB = new ListNode(2);
var nodeC = new ListNode(1);
nodeA.next = nodeB;
nodeB.next = nodeC;
nodeC.next = null;
isPalindrome(nodeA)
方法三 快慢指针
- 定义4个变量
- 快指针
- 慢指针
- 慢指针慢1步
- 指向后半段的头结点
- 如果是奇数个节点
- pre
- 指向前半段的头结点
- cur
- 先找到中间节点
- 如何确定找到?
- 结束条件
- 快指针的 next 为 null 即为到了最后
- 结束条件
- 前半部分反转
- 与后半部分链表数据进行比较
- while 循环,每个值进行比较
- 有一个不同即为不同
- 如何确定找到?
- 复杂度
- 总共遍历了1次,两次都是一半,所以时间复杂度是 O(n)
- 用了4个变量,空间复杂度是 O(1)
var isPalindrome = function(head) {
if(!head || !head.next) return true;
let fastRef = head,
slowRef = head,
cur = head,
pre = null;
while(fastRef && fastRef.next) {
slowRef = slowRef.next;
fastRef = fastRef.next.next;
const nextTemp = cur.next;
cur.next = pre;
pre = cur;
cur = nextTemp;
}
// 快指针已经到结尾
if (fastRef) {
// 奇数个
slowRef = slowRef.next;
}
while(pre) {
if (pre.val !== slowRef.val) return false;
pre = pre.next;
slowRef = slowRef.next;
}
return true;
};
1-2 👌环形链表
这些不是环形链表:
- 空链表
- 只有一个节点的链表
最常见的有三种方法判断:
- 双指针法
- 哈希表法
- 利用 Symbol 的特性
双指针
- 空链表
- 不为空链表
- 一个节点的链表
- 链表不为空,走到了链表末尾
- 链表不为空,两个指针总会相遇
- 时间复杂度 O(n)
- 空间复杂度 O(1)
var hasCycle = function(head) {
if(!head || !head.next) return false
let slowRef = head,
fastRef = head
while(fastRef && fastRef.next) {
fastRef = fastRef.next.next
slowRef = slowRef.next
if(fastRef === slowRef) return true
}
return false
};
哈希表法
- 时间复杂度 O(n)
- 空间复杂度 O(n)
- 所需的额外空间取决于哈希表存储的元素数量,最多需要存储 n 个元素
var hasCycle = function(head) {
if(!head || !head.next) return false
const hashMap = new Map()
while(head) {
if(hashMap.has(head)) return true
hashMap.set(head, head.val)
head = head.next
}
return false
};
Symbol法
- 把遍历过的节点的 val 都放同一个 symbol
- 如果遍历到了这个 symbol,就是环形链表
- 如果链表结束了,不是环形链表
var hasCycle = function(head) {
if(!head || !head.next) return false
const symbol = Symbol()
while(head) {
if(head.val === symbol) return true
head.val = symbol
head = head.next
}
return false
};
1-3 👌删除链表中的节点
说明:
- 链表至少包含两个节点。
- 链表中所有节点的值都是唯一的。
- 给定的节点为非末尾节点并且一定是链表中的一个有效节点。
- 不要从你的函数中返回任何结果。
- 删除链表的节点
- 从链表里删除一个节点 node 的最常见方法是修改之前节点的 next 指针,使其指向之后的节点
- 注意
- JS中基本类型按值引用,对象类型按地址引用
- 直接 node = node.next 是错误的
有2个办法
- Object.assign
- 直接覆写
var deleteNode = function(node) {
Object.assign(node, node.next)
};
var deleteNode = function(node) {
node.val = node.next.val
node.next = node.next.next
};
2-1 👌翻转单链表
有3个办法
- 迭代法
- 递归
- 尾递归
1、迭代法
- 复杂度
- 时间 O(n)
- 空间 O(1)
- 不要忘记在最后返回新的头引用!
- 执行用时:64 ms, 在所有 JavaScript 提交中击败了94.70%的用户
- 内存消耗:35.4 MB, 在所有 JavaScript 提交中击败了42.86%的用户
/**
* Definition for singly-linked list.
* function ListNode(val) {
* this.val = val;
* this.next = null;
* }
*/
/**
* @param {ListNode} head
* @return {ListNode}
*/
var reverseList = function(head) {
// 如果链表为空或者只有一个节点,返回 head
if(!head || !head.next) return head;
let [prev, cur] = [null, head]
while(cur) {
const nextTemp = cur.next;
cur.next = prev;
prev = cur;
cur = nextTemp;
}
return prev;
};
2、递归法
- 执行用时:80 ms, 在所有 JavaScript 提交中击败了31.75% 的用户
- 内存消耗:36 MB, 在所有 JavaScript 提交中击败了7.14%的用户
- 复杂度
- 时间 O(n)
- 空间 O(n)
- 思路
- 不断裁剪
- [1,2,3]
- 1 和 [2,3]
- [2,3] 分为 2 和 3
- 3 到了最后,直接返回
- [1,2,3]
- 不断裁剪
/**
* Definition for singly-linked list.
* function ListNode(val) {
* this.val = val;
* this.next = null;
* }
*/
/**
* @param {ListNode} head
* @return {ListNode}
*/
var reverseList = function(head) {
if(!head || !head.next) return head;
var next = head.next;
var reverserHead = reverseList(next);
next.next = head;
head.next = null;
return reverserHead;
};
3、尾递归
由于递归调用而在系统调用栈上产生的隐式额外空间。然而,你应该学习识别一种称为尾递归的特殊递归情况,它不受此空间开销的影响
尾递归函数是递归函数的一种,其中递归调用是递归函数中的最后一条指令。并且在函数中应该只有一次递归调用。
节省空间
- 尾递归的好处是,它可以避免递归调用期间栈空间开销的累积,因为系统可以为每个递归调用重用栈中的固定空间。
解法
- prev = curr
- curr = next
复杂度
- 时间 O(n)
- 空间 ?
执行用时:68 ms, 在所有 JavaScript 提交中击败了 85% 的用户
内存消耗:35 MB, 在所有 JavaScript 提交中击败了 21%的用户
var reverseList = function(head) {
let reverse = (prev, cur) => {
if (!cur) return prev;
const nextTeamp = cur.next;
cur.next = prev;
return reverse(cur, nextTeamp);
}
return reverse(null, head)
};
2-2 👌删除链表的倒数第N个节点
双指针法
- 快指针先前进 n 个
- 如果快指针 = null,代表删除 head,直接返回 head.next
- 然后快慢指针一起走
- 等到快指针的下一个节点是 null 的时候
- 慢指针的下一个节点就是要删除的节点
var removeNthFromEnd = function(head, n) {
let first = head,second = head;
while(n > 0) {
first = first.next;
n--;
}
if(!first) return head.next;
while(first.next) {
second = second.next;
first = first.next;
}
second.next = second.next.next;
return head;
};
2-3 👌合并两个有序链表
- 递归法
- 复杂度
- 时间 O(n+m)
- n 和 m 是两个链表的长度
- 击败了43%的用户
- 空间 O(n+m)
- 击败了85%的用户
- 每次递归调用一次,耗费 O(1)的栈空间
- 时间 O(n+m)
- 复杂度
- 双指针法
- 创建一个新的链表
- head 为 -1
- 实际返回 head.next
- 依次判断 l1 和 L2
- 直到有一个指针指向 null
- 然后新链表再续着剩下的元素
- 复杂度
- 时间 O(n+m)
- n 和 m 是两个链表的长度
- 击败了62.58%的用户
- 空间 O(1)
- 申请了一个指针空间
- 击败了70%的用户
- 时间 O(n+m)
- 创建一个新的链表
// 双指针法
var mergeTwoLists = function(l1, l2) {
// 创建一个新节点
const head = new ListNode(-1)
let cur = head
// 如果两个链表都非空
while(l1 && l2) {
if(l1.val <= l2.val) {
cur.next = l1
l1 = l1.next
}
else {
cur.next = l2
l2 = l2.next
}
cur = cur.next
}
// l1 或 l2剩下的元素
cur.next = l1 || l2
return head.next
};
2-4 👌两数相加
给出两个非空的链表用来表示两个非负的整数。其中,它们各自的位数是按照 逆序 的方式存储的,并且它们的每个节点只能存储 一位 数字。
- 游标法
- 涉及到进位
- 数字相加法
- 将链表先转化为数字
- 要用
BigInt转化字符串- 考虑存在过大的数字相加,此处数字使用BigInt类型
- 要用
- 两个数字相加
- 普通的加法
- 然后再将数字转化为链表
- 可以把数字转化为字符串,倒着遍历
- 将链表先转化为数字
// 两树相加
var addTwoNumbers = function(l1, l2) {
var nodeList2num = function(node) {
var str = ''
while(node) {
str = `${node.val}${str}`
node = node.next
}
return BigInt(str)
}
var num2nodeList = function(num) {
var head = new ListNode(-1)
var cur = head
for(var i = (`${num}`.length) - 1; i >= 0; i--) {
cur.next = new ListNode(`${num}`[i])
cur = cur.next
}
return head.next
}
return num2nodeList(nodeList2num(l1) + nodeList2num(l2))
};
3-1 排序链表
3-2 相交链表
3-3 奇偶链表
给定一个单链表,把所有的奇数节点和偶数节点分别排在一起。请注意,这里的奇数节点和偶数节点指的是节点编号的奇偶性,而不是节点的值的奇偶性。
3-4 相交链表
编写一个程序,找到两个单链表相交的起始节点。
栈 Stack
- 栈既可以用数组来实现,又可以用链表来实现。
- FILO
- first in last out
- 实现可以是数组或者链表
- 应用
- 最小栈
- 有效的括号
- 删除字符串中的所有相邻重复项
class Stack {
constructor() {
this.data = []
}
push(item) {
this.data.push(item)
}
pop() {
return this.data.pop()
}
get length() {
return this.data.length
}
}
155:最小栈(包含getMin函数的栈)
字节&leetcode
leetcode20:有效的括号
腾讯&哔哩哔哩
leetcode1047:删除字符串中的所有相邻重复项
leetcode1209:删除字符串中的所有相邻重复项 II
删除字符串中出现次数 >= 2 次的相邻字符
队列 Queue
- FIFO
- 实现可以是数组或者链表
- 应用
- 用两个栈实现队列
- 翻转字符串里的单词
- 无重复字符的最长子串
class Queue {
constructor() {
this.data = []
this.head = 0
this.tail = 0
}
enqueue(item) {
this.data[this.tail++] = item
}
dequeue() {
if(this.head === this.tail) {
return null
}
return this.data[++this.head]
}
get length() {
return this.tail - this.head
}
}
使用队列对数据进行排序(基数排序)
优先队列
1-1 剑指offer09:用两个栈实现队列
var CQueue = function() {
class Stack {
constructor() {
this.data = []
}
push(item) {
this.data.push(item)
}
pop() {
return this.data.pop()
}
peek() {
return this.data[this.data.length - 1]
}
isEmpty() {
return this.data.length === 0
}
get length() {
return this.data.length
}
}
this.stack1 = new Stack()
this.stack2 = new Stack()
};
/**
* @param {number} value
* @return {void}
*/
CQueue.prototype.appendTail = function(value) {
this.stack1.push(value)
};
/**
* @return {number}
*/
CQueue.prototype.deleteHead = function() {
if(this.stack2.isEmpty()) {
if(this.stack1.isEmpty()) return -1
while(!this.stack1.isEmpty()) {
this.stack2.push(this.stack1.pop())
}
}
return this.stack2.pop()
};
/**
* Your CQueue object will be instantiated and called as such:
* var obj = new CQueue()
* obj.appendTail(value)
* var param_2 = obj.deleteHead()
*/
102 LeetCode 32. 用栈实现队列
https://leetcode-cn.com/problems/implement-queue-using-stacks/
leetcode239:滑动窗口最大值问题
leetcode151:翻转字符串里的单词
字节
Leetcode3:无重复字符的最长子串
字节
栈和队列应用
- 对于栈来说,一个指针就够了
- 但是队列需要两个指针,分别用于指向头部和尾部。
汉明距离
👌有效的括号
遇见匹配的问题,最好的解决方案就是Stack结构,但是JS本身是没有栈结构的,JS可以用数组来实现栈。
- 方法1
- 遍历s
- 如果是左括号就压栈
- 如果是右括号就与栈顶元素进行匹配
- 如果栈为空,return false
- 如果匹配成功 pop()
- 如果遍历完成后,栈中无元素,说明是有效字符串
- 方法2
- 碰到左括号,push 右括号,
- 不是左括号,判断栈是否为空或栈顶元素是否等于当前元素
- 栈为空
- 进来的是右括号 卒
- 栈不为空
- 和栈顶元素不匹配 卒
- 栈为空
- 最终数组是否有元素判断 s 是否有效的括号
- 和方法1的思路类似,不过判断的是相等,不需要用 hashMap
function isValid(s) {
var map = new Map([
['(', ')'],
['{', '}'],
['[', ']'],
])
var stack = []
for(var i = 0; i < s.length; i++) {
if(map.has(s[i])) {
stack.push(s[i])
} else if(!stack.length || map.get(stack.pop()) !== s[i]) {
return false
}
}
return !stack.length
};
// 解法1的变化 不用 hashMap
var isValid = function (s) {
let map = {
'(': -1,
')': 1,
'[': -2,
']': 2,
'{': -3,
'}': 3
}
let stack = []
for (let i = 0; i < s.length; i++) {
if (map[s[i]] < 0) {
stack.push(s[i])
} else {
let last = stack.pop()
if (map[last] + map[s[i]] != 0) return false
}
}
if (stack.length > 0) return false
return true
};
两整数之和
有序矩阵中第K小的元素和多数元素
优先队列
- 优先队列虽通常用堆来实现,但它在概念上与堆不同
- 优先队列不必遵循队列先进先出的规
堆栈、队列比较
题目
- 汉明距离、位 1 的个数、缺失数字
- 有效的括号、帕斯卡三角形和颠倒二进制位
- 两整数之和、数据流的中位数和逆波兰表达式
- Task Scheduler、有序矩阵中第 K 小的元素和多数元素
哈希表
- 又称散列表或者字典
- “字典”是一个概念
- 字典是从应用的角度说的
- 字典注重的是“一个键值(key)对应一个值(value)“的概念,而字典的实现(implementation)既可以是朴素的二维数组,也可以是哈希表
- hashMap
- hashTable
- hashSet
- 理解 Map Table Set 的区别
- 在 Java 中,HashSet不允许重复键且不同步,允许空键,HashMap不是同步的,但是允许重复键,Hashtable是同步的并且允许重复键,它也不允许空键或值
- Set和Map接口指定两种非常不同的集合类型
- Hashtable和HashMap都实现Map,HashSet实现Set,并且它们都对集合中包含的键/对象使用哈希码以提高性能
- “字典”是一个概念
- 哈希表使用
哈希函数/散列函数来计算一个值在数组或桶(buckets)中或槽(slots)中对应的索引,可使用该索引找到所需的值 - 哈希函数处理
k-v的映射
腾讯&leetcode349:给定两个数组,编写一个函数来计算它们的交集
字节&leetcode1:两数之和
腾讯&leetcode15:三数之和
leetcode380:常数时间插入、删除和获取随机元素
剑指Offer:第一个只出现一次的字符
树
- 分类
- 树
- 二叉树(只有2个子节点的树)
- 存储有序元素的绝佳选择
- 二叉树是一种特殊的树,它的子节点个数不超过两个
- 满二叉树
- 如果一个二叉树,每一层的节点数都达到最大值
- k 层,则结点总数为 2 ^ k - 1
- 完全二叉树
- 完全二叉树是由满二叉树而引出来的
- 意思是,除了最后一层外,别的层都满了,而且最后一层所有结点都几种在最左边
- 非完全二叉树
- 二叉查找树
- 又叫二叉搜索树
- 又叫 BST (binary search tree)
- 三叉树
- and so on
- 存储结构
- 链式存储
- 基于数组的顺序存储
- 自上而下、从左到右的顺序存储 n 个节点的完全二叉树
- 只适合完全二叉树
- 如果不是完全二叉树,用这种结构来存储会浪费比较多的空间
二叉树的遍历
- 遍历树的方法。
- DFS:深度优先 depth
- 先序遍历,中序遍历,后序遍历;
- 从根节点开始一直遍历到某个叶子节点,然后回到根节点,在遍历另外一个分支。
- BFS。广度优先
- 按照高度顺序,从上往下逐层遍历节点。
- DFS:深度优先 depth
- 前序遍历
- 中左右
- 中序遍历
- 左中右
- 后序遍历
- 左右中
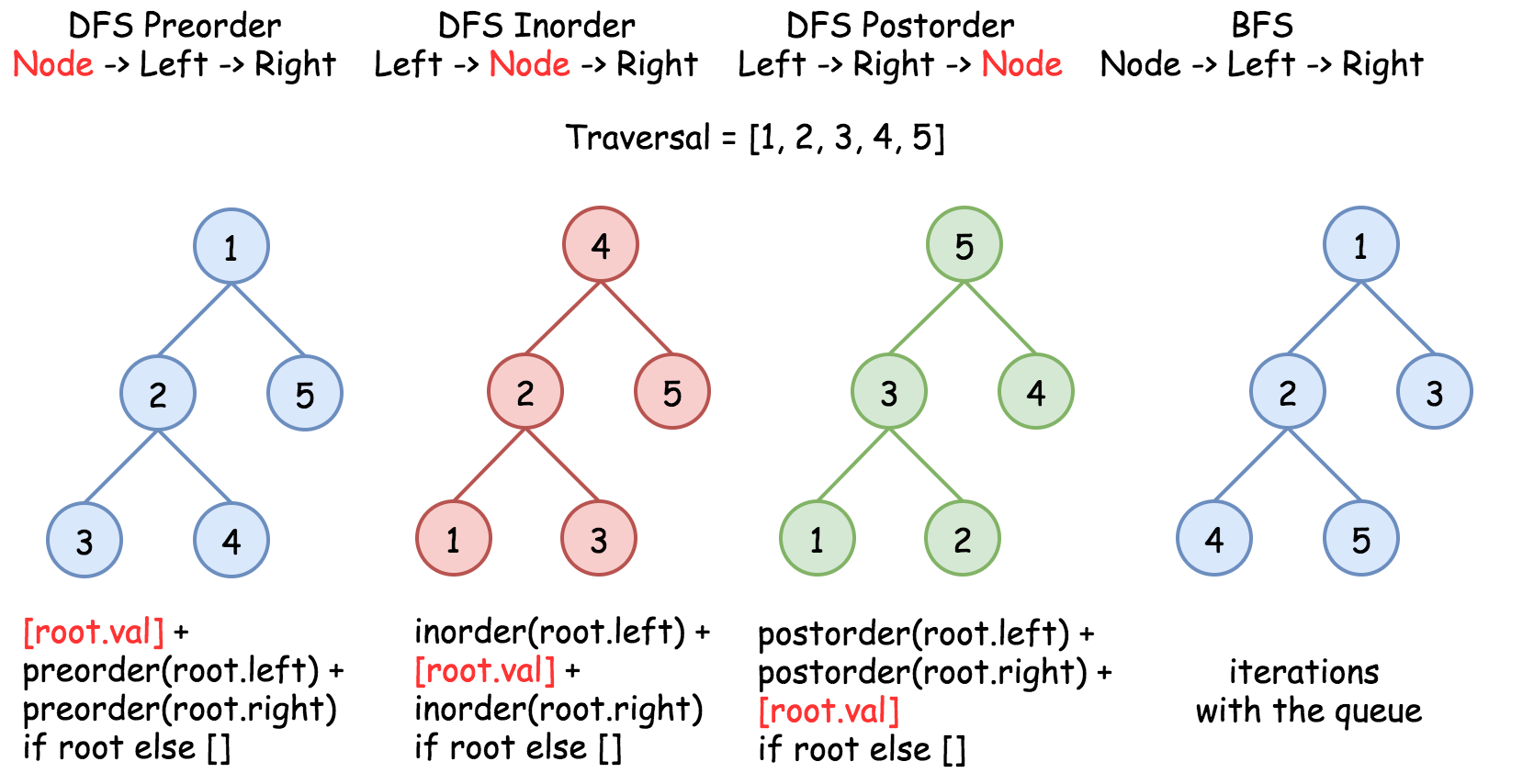
class Node {
data: any;
left?: Node;
right?: Node;
constructor({data, left, right}) {
this.data = data
this.left = left
this.right = right
}
}
二叉查找树 BST (Binar Search Tree)
- 还有一个名字叫做
- 二叉排序树
- 二叉搜索树
- 一种特殊的二叉树
- 相对较小的值保存在左节点
- 相对较大的值保存在右节点
- 查找效率很高
BST 的查找- 找给定值
- 通过比较该值和当前节点上的值的大小,就能够确定向左还是向右遍历
- 找最大值
- 只需遍历右子树,直到找到最后一个节点
- 找最小值
- 遍历左树,找到最后一个节点
- 找给定值
BST 的插入- 先看看有没有根节点
- 没有根节点,是棵新树,该节点就是根节点
- 有根节点,需要遍历整棵树
- 大于当前节点
- 如果右子树为空?
- 为空?
- 不为空
- 继续 node = node.right
- 如果右子树为空?
- 小于当前节点
- 大于当前节点
- 先看看有没有根节点
BST 的删除- 牵一发而动全身
- 待删除节点是叶子节点(没有子节点的节点)
- 只需要把从父节点指向它的指针指向
null
- 只需要把从父节点指向它的指针指向
- 待删除节点包含一个子节点
- 只需要把从父节点指向它的指针指向
子节点
- 只需要把从父节点指向它的指针指向
- 待删除节点包含2个子节点
- 查找节点右子树上的最小值
BST 的遍历- 中序遍历是有序的,使用递归的方式最为简单
- 看看上一节二叉树的遍历
二叉树的自平衡
- 在二叉树中依次插入 9 8 7 6 5 4,看看会发生什么?
- 二叉树会
跛脚,都插到左子树去了 - 解决办法
- 红黑树
- AVL 树
- 树堆
二叉堆
- 是
宽松版的二叉查找树 - 是一个
完全二叉树 - 只要求父节点的值大于左右节点就行了
- 实现
- 存储结构不是链式的,是顺序存储,用数组实现
优先队列
- 最大优先队列
- 无论入队顺序如何,都是当前最大的元素优先出队
- 可以用最大堆来实现最大优先队列
- 最小优先队列
- 无论入队顺序如何,都是当前最小的元素优先出队
- 可以用最小堆来实现最小优先队列
1-1 👌最小栈
/**
* initialize your data structure here.
*/
var MinStack = function() {
this.stack = []
this.minStack = []
};
/**
* @param {number} x
* @return {void}
*/
MinStack.prototype.push = function(x) {
this.stack.push(x)
if(this.minStack.length === 0) {
this.minStack.push(x)
} else {
var min = Math.min(this.minStack[this.minStack.length - 1], x)
this.minStack.push(min)
}
};
/**
* @return {void}
*/
MinStack.prototype.pop = function() {
this.stack.pop()
this.minStack.pop()
};
/**
* @return {number}
*/
MinStack.prototype.top = function() {
return this.stack[this.stack.length - 1]
};
/**
* @return {number}
*/
MinStack.prototype.getMin = function() {
return this.minStack[this.minStack.length - 1]
};
1-2 👌打乱数组
- Fisher-Yates 洗牌算法
- 让数组中的元素互相交换
- 在每次迭代中,生成一个范围在当前下标到数组末尾元素下标之间的随机整数
- 当前元素是可以和它本身互相交换的 - 否则生成最后的排列组合的概率就不对了
- 复杂度
- 空间 O(n) 因为要实现 重置 功能,原始数组必须得保存一份,因此空间复杂度并没有优化。
- 时间 O(n)
- 要遍历所有元素
https://leetcode-cn.com/problems/shuffle-an-array/
/**
* @param {number[]} nums
*/
var Solution = function(nums) {
this.nums = nums
this.originalNums = nums.slice(0)
};
/**
* Resets the array to its original configuration and return it.
* @return {number[]}
*/
Solution.prototype.reset = function() {
this.nums = this.originalNums.slice(0)
return this.nums
};
/**
* Returns a random shuffling of the array.
* @return {number[]}
*/
Solution.prototype.shuffle = function() {
for(var i = this.nums.length - 1; i > 0 ; i--) {
var targetIndex = Math.floor(Math.random() * (i + 1))
var tmp = this.nums[i]
this.nums[i] = this.nums[targetIndex]
this.nums[targetIndex] = tmp
}
return this.nums
};
1-3 👌将有序数组转换为二叉搜索树
108
https://leetcode-cn.com/problems/convert-sorted-array-to-binary-search-tree/
将一个按照升序排列的有序数组,转换为一棵高度平衡二叉搜索树。 本题中,一个高度平衡二叉树是指一个二叉树每个节点 的左右两个子树的高度差的绝对值不超过 1。
- “有序数组 -> BST”有多种答案。
- 中序遍历不能唯一确定一棵二叉搜索树。
- 树的高度应该是平衡的、例如:每个节点的两棵子树高度差不超过 1
- 高度平衡意味着每次必须选择中间数字作为根节点。
- 这对于奇数个数的数组是有用的
- 但对偶数个数的数组没有预定义的选择方案。
- 始终选择中间位置左边的元素作为根节点
- 始终选择中间位置右边的元素作为根节点
- 高度平衡意味着每次必须选择中间数字作为根节点。
- 时间复杂度 O(n) 每个元素都被遍历了一边
- 空间复杂度 O(logn) 递归调用占用的栈空间
- 数组是有序的,代表是中序遍历的结果
- 通过中序遍历的结果是否可以唯一确定一棵树?答案是否定的
var sortedArrayToBST = function(nums) {
var helper = function(left, right) {
if (left > right)
return null
var p = parseInt((left + right) / 2)
// 中间的数一定是最中间的
var root = new TreeNode(nums[p])
// p - 1 和 p + 1 是为了间隔开 parent
// 不断递归
root.left = helper(left, p - 1)
root.right = helper(p + 1, right)
return root
}
return helper(0, nums.length - 1)
};
2-1 leetcode101 对称二叉树
2-2 二叉树的最大深度
2-3 验证二叉搜索树
3-1 二叉树的层次遍历
3-2 二叉树的序列化与反序列化
3-3 常数时间内插入删除
3-4 获得随机数
4-1 中序遍历二叉树
从前序与中序遍历序列构造二叉树和二叉搜索树中第 K 小的元素
5-1 填充每个节点的下一个右侧节点指针
5-2 岛屿数量
5-3 二叉树的锯齿形层次遍历
堆
- 堆(heap) 是一种特殊的基于树的数据结构
- 最小堆
- 最大堆
腾讯&字节等:最小的k个数
leetcode347:前 K 个高频元素
字节&leetcode215:数组中的第K个最大元素
剑指Offer&leetcode295:数据流的中位数
binary heap 二叉堆
- 二进制堆
- 也叫二叉堆
- 二进制堆是堆的特定实现,其中每个父堆最多只能有两个子堆
- 存储
- 二叉堆一般用数组来表示
- 如果根节点在数组中的位置是1,第n个位置的子节点分别在2n和 2n+1
- 优势
- 堆有助于更快地访问最小和最大元素
- 分类
- 最大堆
- 最小堆
- 二叉堆的自我调整
- 通常在插入、删除元素或者构建二叉堆,需要自我调整
- 上浮
- 插入节点
- 下沉
- 删除节点
- 构建二叉堆
- 实现堆
利用数组- heapify
- 插入或删除某个元素后平衡堆的过程称为 heapify
- 向上遍历通常称为 heapifyUp
- 向下遍历堆的过程我们称之为 heapifyDown
- 如何将堆表示为一个 JavaScript 数组
- [100, 19, 36, 17, 3]
- 常见操作
- 移除节点
- 插入节点
- 在数组末尾插入节点
- 然后自下而上调整子节点与父节点的位置
- 不满足堆性质则交换
图
广度优先搜索、深度优先搜索
leetcode997:找到小镇的法官
leetcode207:课程表问题
剑指Offer&Bigo:旋转矩阵
其他数据结构
布隆过滤器
用于索引的数据结构
数据结构比较

- 数组
- 优点是:get和set操作时间上都是O(1)的;
- 缺点是:add和remove操作时间上都是O(N)的
- 链表
- 链表是一种非连续、非顺序的结构
- 优点是:add和remove操作时间上都是O(1)的;
- 缺点是:get和set操作时间上都是O(N)的
- 队列 queue
- 队列是一种特殊的线性表
- 遵循先进先出
- 只允许在表的前端进行删除操作,而在表的后端进行插入操作
- 栈 Stack
- 后进先出(LIFO)
- 仅允许在表的一端进行插入和删除运算。这一端被称为栈顶
- 集合
- 主要特性是元素不可重复
- 散列表
- hashMap
- 根据关键键值(Keyvalue)进行访问的数据结构
- 把关键码值映射到表中一个位置来访问记录,以加快查找的速度,这个映射函数叫做散列函数
- 树
- 二叉树
- 每个结点至多只有二棵子树
- 满二叉树
- 除最后一层无任何子节点外,每一层上的所有结点都有两个子结点
- 满二叉树是完全二叉树的一个特例
- 二叉查找树
- 又称为是二叉排序树(Binary Sort Tree)或二叉搜索树
- 二叉查找树的性质:对二叉查找树进行中序遍历,即可得到有序的数列
- 平衡二叉树 AVL树
- 具有以下性质:它是一棵空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树
- 它的出现就是解决二叉查找树不平衡导致查找效率退化为线性的问题,因为在删除和插入之时会维护树的平衡,使得查找时间保持在O(logn),比二叉查找树更稳定
- 树这种数据结构在计算机世界中有广泛的应用
- 操作系统中用到了红黑树
- 数据库用到了B+树
- 编译器中的语法树
- 内存管理用到了堆(本质上也是树)
- 二叉树
- 堆
- 堆是一颗完全二叉树
- 所有父节点都满足大于等于其子节点的堆叫大根堆,所有父节点都满足小于等于其子节点的堆叫小根堆
- 堆虽然是一颗树,但是通常存放在一个数组中,父节点和孩子节点的父子关系通过数组下标来确定
- 堆的用途:堆排序,优先级队列。
算法
递归算法
- 理解 递 和 归
- 满足递归的三个条件
- 问题可以被分解成几个子问题
- 问题和子问题的求解方法相同
- 递归终止条件
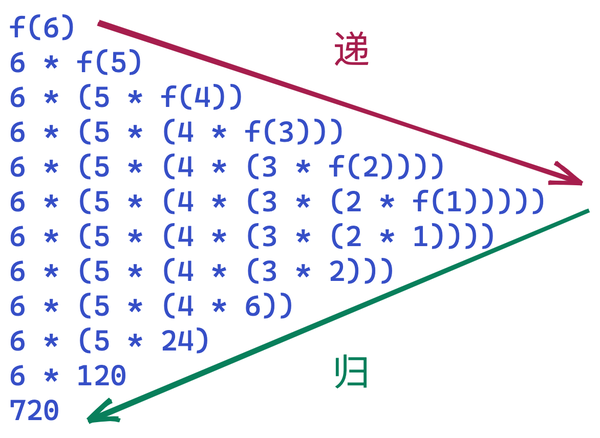
👌斐波那契
分治算法 Divide and Conquer
回溯算法 Backtracking
- 是一种类似尝试算法,按选优条件向前搜索,在搜索尝试过程中寻找问题的解,以达到目标
- 当发现已不满足求解条件时,就
回溯返回,尝试别的路径。
- 当发现已不满足求解条件时,就
- 简单来说,就是找到一条路往前走,能走就继续往前走,不能走就算了,掉头换条路。
- 本质上上暴力枚举
1-1 👌括号生成
- 左括号的数量一定是小于
n的 - 右括号的数量一定是小于左括号的数量的
- 利用递归
- 左括号的数量 = 右括号的数量 = n
var generateParenthesis = function(n) {
var result = []
var helper = function(str = '', l = 0, r = 0) {
if(str.length === n * 2) {
result.push(str)
return
}
if(l < n) {
helper(`${str}(`, l + 1, r)
}
if(r < l) {
helper(`${str})`, l, r + 1)
}
}
helper()
return result
};
1-2 子集
1-3 电话号码的字母组合
2-1 实现数组的全排列
2-2 单词搜索
贪心算法 Greedy
具体是啥,大概描述一下
- 贪心算法总是会找当前的最优解,而不管这一次的选择对后面有没有影响
找零问题
- 要求:硬币最少
- 先找大的
- 然后对剩下的金额求余,再找第二大的
- 直到最后找小面额的
动态规划 DP Dynamic Programming
使用递归去解决问题虽然代码简洁、简单,但是效率不高。很多用递归解决的算法题,如果用动态规范来解决,效率会更高。
- 动态规划思想,把大问题分解成若干小问题,用矩阵记录状态结果。
- 是通过组合子问题的解决,从而解决整个问题的算法
- 适用于子问题不是独立的情况
- 对每个子问题只求解一次
- 所有子问题的解通常被存储在一个数组里面便于访问。
- 传统递归方式解决斐波那契数列有很多重复运算
// 动态规划版本的斐波那契数列
var fib = function(N) {
if(N < 2) {
return N
}
for(var i = 2; i<= N; i++) {
if(i < 2) {
arr[i] = i
} else {
arr[i] = arr[i - 1] + arr[i - 2]
}
}
return arr[N]
};
👌最长公共子串
- 最长公共子序列(Longest Common Subsequence LCS)
- 子串和子序列
- 两个字符串相同位置字符相同
- 两个序列长度不一定相同
- 子串和子序列不同,子序列不要求连续,子序列可以略过一下元素
- 最长公共子串是最长公共子序列的一种特殊情况
function lcs(word1, word2) {
var m = word1.length
, n = word2.length
, max = 0
, maxColumn = 0
, lcsarr = []
for (var i = 0; i < m; ++i) {
lcsarr[i] = []
for (var j = 0; j < n; ++j) {
if (word1[i] === word2[j]) {
if (i === 0 || j === 0) {
lcsarr[i][j] = 1
} else {
lcsarr[i][j] = lcsarr[i - 1][j - 1] + 1
}
} else {
lcsarr[i][j] = 0
}
if (max < lcsarr[i][j]) {
max = lcsarr[i][j]
maxColumn = j
}
}
}
var str = ''
if (max === 0)
return ''
else {
for (; max > 0; max--,
maxColumn--) {
str = word2[maxColumn] + str
}
return str
}
}
👌最长公共子序列
var longestCommonSubsequence = function(text1, text2) {
var len1 = text1.length,
len2 = text2.length,
arr = []
for(var i = 0; i <= len1; i++) {
// 初始化二维数组
arr[i] = []
for(var j = 0; j <= len2; j++) {
if (i === 0 || j === 0) {
arr[i][j] = 0
continue
}
if(text1[i - 1] === text2[j - 1]) {
arr[i][j] = arr[i - 1][j - 1] + 1
} else {
arr[i][j] = Math.max(arr[i][j - 1], arr[i - 1][j])
}
}
}
return arr[len1][len2]
};
👌0 - 1 背包问题 (0 - 1 Knapsack)
- 求可以带走最大多少价值的东西?
- 为啥叫
0 - 1背包- 因为是离散的
- 无法将 ”半台电视” 放入背包
- 离散问题也称为
0 - 1问题 - 必须放入整个物品或者不让入
- 凝缩成一个公式
- F(i, v) = max(F(i - 1, v), F(i - 1, v - vi) + Wi)
- i 代表当前物品
- v 代表剩余容积
- vi 代表当前物品容器
- Wi 代表当前物品价值
- 递归
- 动态规划
- 使用递归能解决的问题,都能使用动态规划解决
- 后一项依赖前几项的值
- 建一个二维数组
- 横坐标是物品容量
- 纵坐标是容器
- 填完二维数组就可以了
- 二维数组最后一个元素就是我们要求的值
// 递归版本
function knapsack(capacity, size, value, n) {
// 背包满了 或者 保险箱空了
if (n === 0 || capacity === 0) return 0;
// 如果容积 大于 剩余的容量,看看下一件物品呢
if (size[n - 1] > capacity) {
return knapsack(capacity, size, value, n - 1);
} else {
return Math.max(
value[n - 1] + knapsack(capacity - size[n - 1], size, value, n - 1),
knapsack(capacity, size, value, n - 1)
);
}
}
// DP 版本
function knapsack(capacity, n, sizes, values) {
var K = []
// 多建一行
for(var i = 0; i <= n; i++) {
K[i] = []
for(var w = 0; w <= capacity; w++) {
// 容积为0,或者物品为0,对应第一行或者第一列
if(i === 0 || w === 0) K[i][w] = 0
// 第 i - 1 个物品放不下
// 不偷
else if (sizes[i - 1] > w) {
K[i][w] = K[i - 1][w]
} else {
// 够放,偷还是不偷?
K[i][w] = Math.max(K[i - 1][w - sizes[i - 1]] + values[i - 1] +, K[i - 1][w])
}
}
}
return K[n][capacity]
}
👌1-1 最大子序和
- 贪心
- 寻找最优解
- 当前值和当前值加上之前和做比较,哪个大取哪个
- 保存一份最大值
- 保存一份之前的和
- 时间 O(n)
- 空间 O(1)
- 寻找最优解
- 动态规划
- 若前一个元素大于 0,则将其添加到当前元素上
- 怎么和贪心算法一样一样的呢
// 贪心算法
function maxSum(arrs) {
var max_sum = arrs[0],
pre_sum = arrs[0]
for(var i = 1; i < arrs.length; i++) {
pre_sum = Math.max(arrs[i], pre_sum + arrs[i])
max_sum = Math.max(max_sum, pre_sum)
}
return max_sum
}
// 动态规划?
function maxSum(arrs) {
var max_sum = arrs[0],
pre = 0;
for (var i = 0; i < arrs.length; i++) {
pre = Math.max(pre + arrs[i], arrs[i])
max_sum = Math.max(max_sum, pre)
}
return max_sum;
}
// LeetCode 视频图解 动态规划版本
function maxSum(nums) {
for (var i = 1; i < nums.length; i++) {
// 前一个元素大于 0 ?
if (nums[i - 1] > 0) {
nums[i] += nums[i - 1];
}
}
return Math.max(...nums);
}
// 判断是否有增益效果
function maxSum(nums) {
var sum = nums[0],
max = nums[0]
for(var i = 1; i < nums.length; i++) {
// 之前的值大于0,
if(sum > 0) {
// 正数 + 一个正数或者负数
sum += nums[i]
} else {
// 如果之前的值小于0,不要之前的值了,
// 负数加上一个正数,< 正数
// 负数加上一个负数 < 负数
sum = nums[i]
}
max = Math.max(sum, max)
}
return max
}
1-2 爬楼梯
1-3 买卖股票的最佳时机
2-1 打家劫舍
2-2 零钱兑换
2-3 跳跃游戏
3-1 不同路径
3-2 单词拆分
排序算法
- 稳定性
- 如果只按照第一个数字排序的话
- 第一个数字相同而第二个数字不同的话
- 第二个数字按照原有排序的就是稳定排序
- 不按照原有排序的就是不稳定排序
- 时间复杂度
- 一般而言,好的表现是O(nlogn),且坏的行为是O(n2)
| 排序方法 | 时间复杂度(最坏) | 空间复杂度 | 稳定性 |
|---|---|---|---|
| 冒泡排序 | O(n2) | O(1) | 稳定 |
| 选择排序 | O(n2) | O(1) | 不稳定 |
| 插入排序 | O(n2) | O(1) | 稳定 |
| 希尔排序 | O(n2) | O(1) | 不稳定 |
| 归并排序 | O(nlogn) | O(n) | 稳定 |
| 快速排序 | O(n2) | O(nlogn) | 不稳定 |
- 插入排序比冒泡、选择排序快
- 快排是最好的排序算法
- 堆排序为啥不好呢?
- 快排要比堆排序快得多
- 其他排序算法
- 堆排序
- 依次出堆头,都是最小元素(最小堆)
- 用数组实现最小堆
- 基数排序
- 计数排序
- 桶排序
- 堆排序
排序算法可视化
https://sqdxwz.top/post/VT62e2oy8/
👌冒泡排序 bubbleSort
- 比较容易实现,但是比较慢
- 最简单最容易理解的排序算法之一
- 把大元素一步一步的冒泡到数组末尾的算法
- 步骤
- 先从第一个数开始,每次比较相邻的元素,如果第二个比第二个大,就交换位置,从开始第一队到结尾最后一对。这一步做完后,最后的元素会是最大的数
- 然后从第二个数开始,一对一对的比较,一直比较到倒数第二个(因为最后一个是最大的),比较完之后,倒数第二个元素会是第二大的元素
- 实现
- 两层 for 循环
- 每一次最外层的 for 循环,把一个最大值冒泡到了数组的最后
- 外层循环 遍历
length - 1次 - 内层循环
length - 1 - i次
- 两层 for 循环
function bubbleSort(arr) {
const len = arr.length;
for (let i = 0; i < len - 1; i++) {
for (let j = 0; j < len - 1 - i; j++) {
if (arr[j] > arr[j+1]) {
const temp = arr[j+1];
arr[j+1] = arr[j];
arr[j] = temp;
}
}
}
return arr;
}
function bubbleSort(nums) {
var numElements = nums.length
var temp
for( var outer = numElements; outer >= 2; --outer) {
for( var inner = 0; inner <= outer - 2; ++inner) {
if(nums[inner] > nums[inner + 1]) {
temp = nums[inner]
nums[inner] = nums[inner + 1]
nums[inner + 1] = temp
}
}
}
return nums
}
👌选择排序 selectionSort
- 是一种简单直观的排序算法
- 为啥叫选择呢,理解一下?
- 从第1个元素,依次和剩下的元素比较,找到最小值,和数组第1个元素交换
- 再从第2个元素开始,找到最小的元素,和数组第2个元素交换
- 步骤
- 依次把最小值放在数组的前面
- 每一次遍历,把最小的值选择到数组的最前面
- 第一次遍历
arr[0] 和 arr[1] - arr[arr.length - 1]比
- 第二次遍历
arr[] 和 arr[2] - arr[arr.length - 1]比
- ...
function selectionSort(arr) {
var minIndex
var tmp
for(var i = 0; i < arr.length - 1; i++) {
minIndex = i
for(var j = i + 1;j < arr.length; j++) {
// 卧槽 还有比我小的
if(arr[j] < arr[minIndex] ) {
minIndex = j
}
}
tmp = arr[i]
// 交换这俩货
arr[i] = arr[minIndex]
arr[minIndex] = tmp
}
return arr
}
👌插入排序 insertionSort
- 类似于按首字母或者数字对数据进行排序
- 原理
- 对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。
- 分为
- 直接插入排序
- 基于顺序查找
- 使用双层循环
- 对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入
- 二分插入排序
- 基于二分查找
- 插入排序和冒泡排序一样,也有一种优化算法,叫做拆半插入。
- 希尔排序
- 基于逐渐缩小增量
- 优化版的插入排序
- 直接插入排序
- 稳不稳?
- 稳定的
- 即两个相等的数不会交换位置
- 快不快?
- 时间复杂度 O(n^2)
- 空间复杂度 O(1)
- 记住,插入排序比冒泡、选择要快
- 选择排序比冒泡排序快
// 这个方法有问题,看看后面的实现
// function insertionSort(arr) {
// var index
// var tmp
// for(var i = 1;i < arr.length; i++) {
// // 和前面的数组依次进行排序
// index = i
// while(arr[index] < arr[index - 1] && index > 0) {
// // 交换 2 个元素的位置
// tmp = arr[index - 1]
// arr[index - 1] = arr[index]
// arr[index] = tmp
// // 指针往前走
// index--
// }
// }
// return arr
// }
function insertionSort(arr) {
const len = arr.length;
let preIndex;
let current;
for (let i = 1; i < len; i++) {
preIndex = i - 1;
current = arr[i];
// 大于新元素,将该元素移到下一位置
while (preIndex >= 0 && arr[preIndex] > current) {
// 大元素放后面,留个位置给人家插入
arr[preIndex + 1] = arr[preIndex];
// 再看前一个元素
preIndex--;
}
// 前一个元素不大于当前元素,把当前元素赋值比较值
// 插入这个元素
arr[preIndex + 1] = current;
}
return arr;
}
👌希尔排序 shellSort - 插入改进版
- 希老爷子(Donald Shell)创造的
- 也称递减增量排序算法
- 和插入排序比
- 不同之处在于,它会优先比较距离较远的元素,而不是相邻的元素
- 希尔排序对插入排序做了很大的改善
- 希尔排序是非稳定排序算法,插入排序是稳定排序
- 插入排序是低效的, 每次只能将数据移动一位
- 最后一次间隔是1,是一次插入排序
- 间隔序列
- 可以随便取,
- 最后一个间隔必须是1
- 你也可以不断 / 2
- 一些小技巧
- for 循环 和 while 循环可以相互转换
- for 循环的第二个条件可以用 && 符号,把 {} 里面的 if 语句放到这里第二个条件这里
function shellSort(arr) {
var tmp
for (var D = Math.floor(arr.length / 2); D >= 1; D = Math.floor(D / 2)) {
// 从 gap 逐渐递增+1,一直到数组的最后
for (var P = D; P <= arr.length - 1; P++) {
// 暂存当前要比较的元素
tmp = arr[P]
// 递减间隔 gap 个,往前看,如果前面的大于后面的,把前面的往后挪
for (var Q = P; Q >= D && arr[Q - D] > tmp; Q -= D) {
arr[Q] = arr[Q - D]
}
// 到达最前面了,插入吧
// 这里 Q 是可以访问的
arr[Q] = tmp
}
}
return arr;
}
动态间隔序列
// gap 依次是 4 和 1
function shellSort(arr) {
var len = arr.length,
temp,
gap = 1;
while(gap < len/3) { //动态定义间隔序列
gap = gap * 3 + 1;
}
for (gap; gap > 0; gap = Math.floor(gap/3)) {
for (var i = gap; i < len; i++) {
temp = arr[i];
for (var j = i-gap; j >= 0 && arr[j] > temp; j-=gap) {
arr[j+gap] = arr[j];
}
arr[j+gap] = temp;
}
}
return arr;
}
👌快速排序 quickSort
- 一般用来处理大数据集,速度比较快
- 采用二分法的思维方式
- 步骤
- 调一个元素,作为基准值
- 小于基准值的扔左边,大于的扔右边
- 依次对两个分出来的数组进行递归操作
- 最后合并起来
- 围绕基准进行数据排序
- 基准值
- 随便取,不影响结果
- 我们这里取第一个好了
- 基准值
function qSort(arr) {
if(arr.length === 0) return []
var lessArr = [],
greaterArr = [],
// 基准值取第一个元素
// 可以随便取
pivot = arr[0]
// i = 1, 从第二个元素开始比较
for(var i = 1; i <= arr.length - 1; i++) {
if(arr[i] < pivot) {
lessArr.push(arr[i])
} else {
greaterArr.push(arr[i])
}
}
return qSort(lessArr).concat(pivot, qSort(greaterArr))
}
👌归并排序 mergeSort
- 把一系列排好序的子序列合并成一个大的完整有序序列
- 合并排序可以更好地处理大量数据。如果您不知道需要多少数据,请考虑使用另一种算法(例如插入排序),以确保数据集足够小以达到两全其美的效果。
- 有 2 种办法
- 自顶向下
- 采用二分法
- 使用递归,递归深度太 TM 深了
- 先分开 递归的将数组两两分开直到最多包含两个元素
- 再合并
- 然后将数组两两排序合并,最终合并为排序好的数组。
- 怎么比较呢?
- 双指针
- 依次比较两个数组的头,谁小,谁指针++
- 自底向上
- 这个实现起来太繁琐了
- 非递归实现
- 1 将序列中带排序数字分为若干组,每个数字分为一组
- 2 将若干个组两两合并,保证合并后的组是有序的
- 3 重复第二步,直到只剩下一组,排序完成
- 自顶向下
// Merge Sort Implentation (Recursion)
function mergeSort (unsortedArray) {
// No need to sort the array if the array only has one element or empty
if (unsortedArray.length <= 1) {
return unsortedArray;
}
// In order to divide the array in half, we need to figure out the middle
const middle = Math.floor(unsortedArray.length / 2);
// This is where we will be dividing the array into left and right
// 递归到最后,只剩下包含一个元素的数组
const left = mergeSort(unsortedArray.slice(0, middle));
const right = mergeSort(unsortedArray.slice(middle));
// Using recursion to combine the left and right
// 使用递归组合左右
return merge(left, right);
}
// Merge the two arrays: left and right
function merge (left, right) {
let resultArray = [], leftIndex = 0, rightIndex = 0;
// We will concatenate values into the resultArray in order
// resultArray 是有序的
while (leftIndex < left.length && rightIndex < right.length) {
// 左边第一个元素小于右边第一个元素
if (left[leftIndex] < right[rightIndex]) {
// 放进结果数组
resultArray.push(left[leftIndex]);
// 左指针加一,和右指针再进行比较
leftIndex++; // move left array cursor
} else {
resultArray.push(right[rightIndex]);
rightIndex++; // move right array cursor
}
}
// We need to concat here because there will be one element remaining
// from either left OR the right
// 我们需要在这里进行合并,因为左侧或右侧会剩下一个元素
return resultArray
.concat(left.slice(leftIndex))
.concat(right.slice(rightIndex));
}
// merge 还可以这么写
const merge = (arr1, arr2) => {
let sorted = [];
while (arr1.length && arr2.length) {
// 每次只比较 arr1 arr2 的第一个元素
// arr1 头部弹出
if (arr1[0] < arr2[0]) sorted.push(arr1.shift());
// arr2 头部弹出
else sorted.push(arr2.shift());
};
// 有一个漏网之鱼
return sorted.concat(arr1.slice().concat(arr2.slice()));
};
function sort(arr) {
if (arr.length === 1) return arr;
var pivot = Math.floor(arr.length / 2);
var leftarr = sort(arr.slice(0, pivot));
var rightarr = sort(arr.slice(pivot));
function merge(left, right) {
var res = [];
while (left.length > 0 && right.length > 0) {
if (left[0] < right[0]) res.push(left.shift());
else res.push(right.shift());
}
return res.concat(left.slice(), right.slice());
}
return merge(leftarr, rightarr);
}
堆排序
- 原理
- 最大堆的堆顶是整个堆中的最大元素
- 最小堆的堆顶是整个堆中的最小元素
- 步骤
- 先要把无序数组构建成二叉堆
- 从小到大排序,构建最大堆
- 循环删除堆顶元素,调整堆产生新的堆顶,每次堆顶的元素都是最大的,😁😆
- 先要把无序数组构建成二叉堆
- 时间复杂度
- O(nlogn)
- 空间复杂度
- O(1) 没有开辟额外的集合空间
- 和快排相比
- 快排时间复杂度 O(n^2)
- 快排空间复杂度 O(logn)
计数排序、桶排序、基数排序
前面介绍的排序都需要基于比较,还有 3 种排序算法不需要比较,甚至可以做到线性的时间复杂度
JS 内部 sort 排序
对于 JS 来说,数据量小,使用插入排序,数组长度大于 10 会采用快排,【新的 V8 引擎改成归并排序了,原因是快排不稳定】。
1-1 合并两个有序数组
第一个错误的版本和搜索旋转排序数组
2-1 在排序数组中查找元素的第一个和最后一个位置
数组中的第 K 个最大元素和颜色分类
3-1 前 K 个高频元素
寻找峰值和合并区间
4-1 搜索二位矩阵 II
计算右侧小于当前元素的个数
其他算法
查找算法
- 列表搜索
- 分为顺序查找和二分查找
- 如果你要查找的数据是有序的,二分查找要比顺序查找算法更高效
- 分为顺序查找和二分查找
- 图表搜索
- 深度优先搜索
- 广度优先搜索
// 然后 data 出现的位置
function binSearch(arr, data) {
var upperBound = arr.length - 1,
lowerBound = 0
while(lowerBound <= upperBound) {
var mid = arr[Math.floor((upperBound + lowerBound) / 2)]
if(arr[mid] < data) {
lowerBound = mid + 1
} else if (arr[mid] > data){
upperBound = mid - 1
} else {
return mid
}
}
return -1
}
剪枝
哈希算法
将 k 映射成 v,
- 常见的哈希算法有 MD5, SHA-1(20个字节)、SHA-2(现在常用)
- 哈希算法不可逆
- 相同的输入一定得到相同的哈希值
- 输入完全不同的数据,输出相同的哈希值也会以低概率出现(哈希碰撞)
- 开链法
- 线性探测法
- 哈希与加密有很大区别
字典树
并查集
位运算(二进制)
布隆过滤器
👌 应用 - LRU 缓存算法
为啥有这个算法
- 比如创建一个哈希表作为缓存,但是用户量越来越大,把内存给撑爆了,要求我们把低频的用户给删掉
- LRU 全称 Least Recently Use,最近最少使用的意思
- 怎么实现?
- 用哈希链表
- 链表最左端是最少被访问的
- 链表右端是高频访问的
- 链表中如果没有的数据,插入到链表末尾
- 访问链表数据,取出插入链表最右端
- 缓存容量达到上限了,删除链表最左端的,在最右端插入
五种算法模式比较
- 递归
- 分治
- 动态规划
- 贪心
- 回溯
贪心:一条路走到黑,没有后悔药 回溯:一条路走到黑,有后悔药 动态规划:上帝视角
DP 方程
切题四件套
- 先思考各种边界条件
- 思考各种解,比较时间复杂度
- coding
脑图
